Revit API Trends and Team Meeting in Bretagne
Here is an illuminating explanation by Arnošt Löbel and Martin Schmid on some Revit API development trends that have already been underway for a couple of releases.
Before I get to them, a quick report from our ADN team meeting:
ADN European Team Meeting in Bretagne
As you may have noticed from Adam Nagy's tweets in the past few days, I am at a team meeting with my European ADN colleagues:

We are convening in Brittany, home of our manager Cyrille Fauvel.

The hotel has a nice view of the wild Atlantic Ocean coast:

Here we are at lunch, except for Adam, our social media expert photographer:

Unfortunately, I have to leave again today, all too soon, to get back home for the Easter holiday.
Luckily, I was able to experience the landscape at least a little bit after our all-day meeting yesterday by taking a nice walk from our meeting Hôtel Le Château de Sable – 'Kastell-Treaz' in Breton – to the O'Porsmeur restaurant:
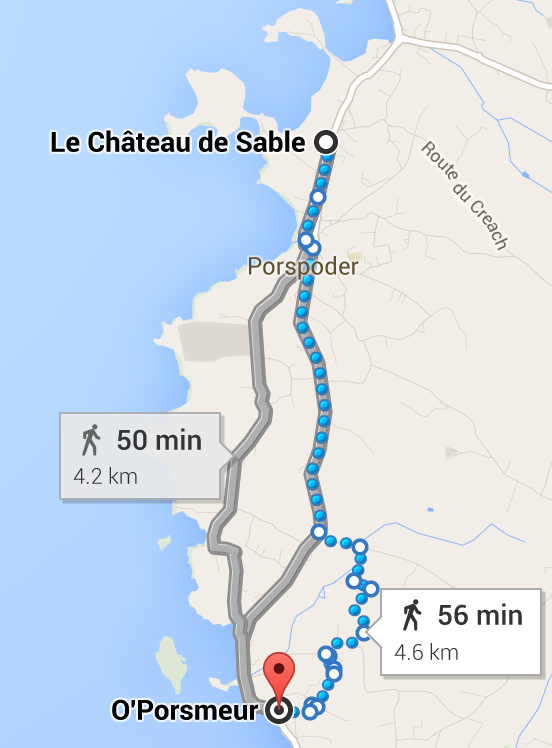
Better still, I was not forced to walk on the roads, but could follow the GR34 hiking path randonnée en Bretagne sur le GR34:
My section from Portsall via Porspoder to Lanildut forms part of its fifth stage from l'Aber-Benoit to Faou.
Back to the Revit API...
Revit API Development Trends
We have had a long-term vision of where the Revit API is headed, and regularly explain what we are aiming for during conferences and meetings, such as the Autodesk University panel sessions and DevDays conferences.
For people who have not attended any such sessions, some changes may seem rather mystifying, disconcerting, ugly or inconvenient.
Such a sentiment prompted this comment by Dave on calculating gross and net wall areas:
Question:
This is pretty much just a gripe, but bear with me if you don't mind. From the diff you posted above:
- foreach( View v in sheet.Views )
+ foreach( ElementId id in viewIds )
{
+ View v = doc.GetElement( id ) as View;
+
What? That's hardly an improvement! Now client code is even more verbose.
Also the old paradigm, if it had been updated to return IEnumerable<View>, would be more amenable to use with Linq queries for post filtering.
I'm not a fan of this one either:
- pipe = doc.Create.NewPipe( q0, q1, - pipe_type_standard ); // 2014 + pipe = Pipe.Create( doc, systemTypeId, + pipe_type_standard.Id, levelId, q0, q1 ); // 2015
For the pipe, I now need to go find a systemTypeId from somewhere, but what if I don't want to assign this at creation time?
Not sure it's doing any good to post this, but I like to vent occasionally.
Answer: Thank you for your comments, which I will reinterpret as constructive questions that raise interesting issues that help illustrate some API design principles and future trends important and worthwhile understanding.
I asked Arnošt Löbel and Martin Schmid for an in-depth explanation, and they reply:
Arnošt: Boy, is that a loaded question of what? Where do I start? I am afraid I cannot give a satisfactory answer and be brief at the same time. I’ll try to answer in stages for that very reason.
A) Very brief explanation
We tend to use functions that take or return element Ids rather then element objects because:
- It’s faster
- It’s safer
- It’s consistent and ties directly to what Revit does internally
B) Detailed and boring explanation
When we originally exposed the API (2005?), there was no direct link between the API and internal Revit code. That had turned out to be a maintenance nightmare. As the API has developed from tiny to large and huge we have realised we simply cannot maintain two parallel hierarchies. That’s why we have developed a framework that allows us to generate the public API directly from the internal native code. Now, basically, what we Revit programmers see, the API programmer gets. Sometime we add certain public method for the API programmer’s convenience, but the majority of the API is pretty much a mirror of Revit internal classes and interfaces.
This applies both to the case of methods using Ids as well as the originally used element creating factories. For the latter, it’s very straightforward: We simply do not have such factories internally and we would not like having them. We believe that element creation is easier when it lives with the element class itself. It is also discoverable better that way.
As for the element Ids - it has been part of Revit coding standard pretty much since ever. I mentioned that the main reasons are safety and speed. We often can do with just element Ids because that allows us to use elements without loading them to memory. For example, if I am looking for certain kind of a view, I can quickly get a list of their Ids, test what they are without expanding them (this is a fast test), and then only get the view I need. That mean I would be expanding one potential element only instead of, say, some hundred of view elements.
The safety aspect has to do with the fact that element objects can become inaccessible when deleted (naturally) or undone or redone. Such operations are not always obvious or visible to the internal programmer who holds a pointer to an element, which leads to very undesirable problem of dangling, invalid pointers. If the programmer uses the element's Id instead, however, then operations on the element are safe. All the programmer needs to do is to test if the element obtained for the given Id is NULL or not. Yes, it is somehow less convenient, but it is incomparably safer with almost no performance penalty. We have made internal element lookup so fast, that it is practically instant.
C) The case of Pipe creation
On top of the above explanation, there is more about this API that perhaps deserves further explanation. I would need to talk to the MEP team to be certain, but I have seen the pattern in other APIs, thus I assume my guess will be very close to what the MEP folks would tell me. The changes the user sees in 2015 are due to our continuing effort to separate Revit UI layer from the underlying model, to which we typically refer to as Revit DB. Without going into great details, the separation between those two should be such that the DB does not know about the UI, while the UI can know about the DB. Makes sense? So, even though it is not apparent when looking at the original pre-2015 pipe creation, the method (which is obviously a DB method) used to reach out to the UI layer to fetch the current type a pipe would be created with if the creation started via the UI. That, for us, is no longer acceptable and it is not how Revit works internally. The original pipe-creation method did what it did because it was written manually and did not reflect Revit internals. With our effort of tying the API tightly with Revit internals, such approach is no longer possible. The API programmer now needs to do what Revit programmers do too, which is:
- If there is UI, find out via the UI interface what the current type is and use that.
- If UI is not accessible (for whatever reason), the programmer simply must know what type is to be used.
I hope my answers are satisfactory. I realise they are not the briefest, but I tried my best.
Martin: Why did we modify the Revit API to require a pipe system type when creating a pipe? – To be consistent with the UI.
Many thanks to Arnošt and Martin for their detailed and succinct explanations, respectively!
I hope this clarifies.