PowerPoint Slide Deck Text Extractor Ppt2txt
Here is another longish post that is not directly related to the Revit API, but rather Microsoft Office programming, more specifically PowerPoint. However, the sample material I present at the end is very directly related to Revit programming, so rest assured that all is well and hopefully interesting.
Contents:
- Slide deck and handout document
- Slide deck comparison and text extraction
- Alternative comparison method
- Ppt2txt usage
- Ppt2txt implementation
- Ppt2txt download
- Formatting in Word
- Sample run
Slide Deck and Handout Document
The Autodesk University class materials will be due one of these days. The deadline is not exactly looming yet, but definitely and inexorably creeping up.
I still need to finish off the handout for my class CP4107 on the new Revit 2013 UI API functionality, probably the most exciting one of my three AU sessions.
I have the sample code for it assembled, both from the DevCamp presentation in June and the brand new UIView, Windows coordinates, ReferenceIntersector and tooltip discussion.
Normally, I think the handout should be finished before I start creating the slide deck. I think the recommended steps for preparing a class should look like this:
- Gather experience.
- Know what you have to share.
- Create compelling illustrative samples.
- Summarise the presentation content in a handout document.
- Create a slide deck to illustrate.
For some reason, however, I sometimes find myself with an existing slide deck in hand, and no handout document yet created.
In that case, I often use the slide deck to create a skeleton handout document by exporting the pure text content of the slide deck and converting that to a document and outline.
In this case, of course, I am aided and abetted in doing this dirty deed by the fact that I already have the finished slide deck from the precursor session at DevCamp.
Slide Deck Comparison and Text Extraction
Another important reason for extracting pure text content from a slide deck is for comparison purposes.
Working on presentations, especially as a group project, I regularly want to find out exactly what changed between one version and another of a given set of PowerPoint slides.
Differences in graphics are often easy to spot, but small changes in the text may also be really important and harder to identify.
Given the pure text content, it is trivial to find and pinpoint them using text comparison tools such as Unix diff and Visual Studio Windiff, of course.
Enter ppt2txt, my very own PowerPoint slide deck text extractor.
I implemented it back in 2007 and have been using it happily ever since.
The thought of sharing it with you guys crossed my mind, so here it is.
Alternative Comparison Method
My colleague Marat Mirgaleev mentioned another way to compare similar slide decks without extracting the text.
The PowerPoint slide deck PPTX format is one of the Microsoft Office Open XML formats, which basically consist of a ZIP compressed archive containing a bunch of XML files and folders.
One of the subfolders contains the slides. Within that folder, each individual slide is represented by a separate XML file. A simple slide by slide comparison of the deck can be performed by comparing the date associated with each one.
Anyway, back to my Ppt2txt text extractor.
Ppt2txt Usage
Usage is simple: you feed it a PPT file, it extracts all the text on all the slides and spits it out in a pure ASCII text file.
By default, the output file path is determined from the input PPT, just replacing the extension. You can use the '-f' option to specify a different output filename or '-' to redirect the output to stdout.
By default, a prefix string 'Title: ' is added in front of each slide title, making it easy to identify and e.g. search and replace the paragraph style of all titles in one fell swoop. If you prefer no such prefix, use the '-t' option to suppress it.
Here is the usage message explaining this a bit more succinctly (copy to a text editor to see the truncated lines in full):
ppt2txt 2.0 * PowerPoint Slide Deck Text Extractor
(C) 2007-2012 Jeremy Tammik Autodesk Inc.
usage: ppt2txt [-f textfilename] [-t] pptfilename
-t: skip adding prefix 'Title: ' to each slide title
-f: write output to textfilename.txt
default: pptfilename.txt
-f-: stdout
Ppt2txt Implementation
Here is the code implementing this:
#region Namespaces using System; using System.IO; using Microsoft.Office.Core; using Ppt = Microsoft.Office.Interop.PowerPoint; using PptType = Microsoft.Office.Interop.PowerPoint.PpPlaceholderType; #endregion // Namespaces namespace ppt2txt { class Program { /// <summary> /// Usage prompt. /// </summary> static string[] _usage = new string[] { "ppt2txt 2.0 * Powerpoint Slide Deck Text Extractor", " (C) 2007-2012 Jeremy Tammik Autodesk Inc.", "usage: ppt2txt [-f textfilename] [-t] pptfilename", " -t: skip adding prefix 'Title: ' to each slide title", " -f: write output to textfilename.txt", " default: pptfilename.txt", " -f-: stdout" }; /// <summary> /// Constant representing 'True' in Powerpoint API. /// </summary> const MsoTriState _t = MsoTriState.msoTrue; /// <summary> /// Windows carriage return + linefeed combination. /// </summary> const string _crlf = "\r\n"; /// <summary> /// Prepend a linefeed to every /// non-empty input string. /// </summary> static string PrependLinefeed( string s ) { return 0 == s.Length ? string.Empty : _crlf + s; } /// <summary> /// Append a new paragraph p to the given text s /// with a linefeed separator in between if s is /// not empty. /// </summary> static string AppendParagraph( string s, string p ) { if( 0 < s.Length ) { s += _crlf; } return s + p; } #region Escape unpleasant Powerpoint characters //static Encoding _ascii = Encoding.ASCII; /// <summary> /// Remove unpleasant non-ascii characters /// that crop up in powerpoint. /// </summary> static string normalise_string( string s ) { s = s.Replace( "…", "..." ); s = s.Replace( '–', '-' ); s = s.Replace( '‘', '\'' ); // backward apostrophe from powerpoint s = s.Replace( '’', '\'' ); // forward apostrophe from powerpoint s = s.Replace( ' ', ' ' ); // strange space char from powerpoint // // quote: // s = s.Replace( '\u0060', '\'' ); // grave accent s = s.Replace( '\u00b4', '\'' ); // acute accent s = s.Replace( '\u2018', '\'' ); // left single quotation mark s = s.Replace( '\u2019', '\'' ); // right single quotation mark s = s.Replace( '\u201C', '"' ); // left double quotation mark s = s.Replace( '\u201D', '"' ); // right double quotation mark // // space: // s = s.Replace( '\x0b', '\n' ); // vertical tab s = s.Replace( '\u0020', ' ' ); // space basic latin s = s.Replace( '\u00a0', ' ' ); // no-break space latin-1 supplement s = s.Replace( '\u1680', ' ' ); // ogham space mark ogham s = s.Replace( '\u180e', ' ' ); // mongolian vowel separator mongolian s = s.Replace( '\u2000', ' ' ); // en quad general punctuation s = s.Replace( '\u2001', ' ' ); // em quad s = s.Replace( '\u2002', ' ' ); // en space s = s.Replace( '\u2003', ' ' ); // em space s = s.Replace( '\u2004', ' ' ); // three-per-em space s = s.Replace( '\u2005', ' ' ); // four-per-em space s = s.Replace( '\u2006', ' ' ); // six-per-em space s = s.Replace( '\u2007', ' ' ); // figure space s = s.Replace( '\u2008', ' ' ); // punctuation space s = s.Replace( '\u2009', ' ' ); // thin space s = s.Replace( '\u200a', ' ' ); // hair space s = s.Replace( '\u202f', ' ' ); // narrow no-break space s = s.Replace( '\u205f', ' ' ); // medium mathematical space s = s.Replace( '\u3000', ' ' ); // ideographic space return s; //using System.Globalization; //using System.Text; //System.Globalization.UnicodeCategory. //s = s.Replace( "", "-->" ); // right arrow //s = s.Replace( '', '\'' ); // backquote Unicode characters //return Encoding.ASCII.GetBytes( s ).ToString(); //return _ascii.GetString( _ascii.GetBytes( s ) ); } #endregion // Escape unpleasant Powerpoint characters /// <summary> /// Get all the text from a given Ppt /// shape, delimited by _crlf. /// </summary> static string GetShapeText( Ppt.Shape shape ) { string s = null; if( _t == shape.HasTextFrame && _t == shape.TextFrame.HasText ) { s = shape.TextFrame.TextRange.Text.Trim(); string[] a = s.Split( new char[] { '\r', '\n' } ); s = string.Empty; foreach( string s2 in a ) { s += PrependLinefeed( s2.Trim() ); } s = s.Trim(); if( 0 == s.Length ) { s = null; } } return s; } static int Main( string[] args ) { // Command line argument values. string filename_in = null; string filename_out = string.Empty; bool title_prefix = true; // Process command line arguments. int n = args.Length; int i = 0; while( i < n ) { string a = args[i]; if( '-' == a[0] ) { if( 't' == a[1] ) { title_prefix = !title_prefix; } else if( 'f' == a[1] ) { filename_out = a.Substring( 2 ); if( 0 == filename_out.Length ) { ++i; if( i >= n ) { Console.Error.WriteLine( "-f option lacks output filename" ); break; } filename_out = args[i]; } } else { Console.Error.WriteLine( string.Format( "invalid option '{0}'", a ) ); break; } } else if( null == filename_in ) { filename_in = a; if( !File.Exists( filename_in ) ) { if( File.Exists( filename_in + ".ppt" ) ) { filename_in = filename_in + ".ppt"; } else if( File.Exists( filename_in + ".pptx" ) ) { filename_in = filename_in + ".pptx"; } } if( !File.Exists( filename_in ) ) { Console.Error.WriteLine( string.Format( "unable to open input file '{0}'", filename_in ) ); break; } } else { Console.Error.WriteLine( string.Format( "invalid argument '{0}'", a ) ); break; } ++i; } if( null == filename_in || !File.Exists( filename_in ) ) { foreach( string s in _usage ) { Console.Error.WriteLine( s ); } return 1; } // Determine full input and output filenames. filename_in = Path.GetFullPath( filename_in ); string ext = "txt"; if( 0 == filename_out.Length ) { filename_out = Path.ChangeExtension( filename_in, ext ); } else if( !filename_out.Equals( "-" ) ) { filename_out = Path.Combine( Path.GetDirectoryName( filename_in ), filename_out + "." + ext ); } // Open output file and process ppt input. using( StreamWriter sw = filename_out.Equals( "-" ) ? new StreamWriter( Console.OpenStandardOutput() ) : new StreamWriter( filename_out ) ) { if( null == sw ) { Console.Error.WriteLine( string.Format( "unable to write to output file '{0}'", filename_out ) ); } else { string s, title, subtitle, body, notes; Ppt.Application app = new Ppt.Application(); app.Visible = _t; Ppt._Presentation p = app.Presentations.Open( filename_in, _t, _t, _t ); foreach( Ppt._Slide slide in p.Slides ) { title = subtitle = body = string.Empty; foreach( Ppt.Shape shape in slide.Shapes ) { s = GetShapeText( shape ); if( null != s ) { if( MsoShapeType.msoPlaceholder == shape.Type ) { switch( shape.PlaceholderFormat.Type ) { case PptType.ppPlaceholderTitle: case PptType.ppPlaceholderCenterTitle: title = AppendParagraph( title, s ); break; case PptType.ppPlaceholderSubtitle: subtitle = AppendParagraph( subtitle, s ); break; case PptType.ppPlaceholderBody: default: // e.g., ppPlaceholderObject body = AppendParagraph( body, s ); break; } } else { body = AppendParagraph( body, s ); } } } // Retrieve notes text. notes = string.Empty; foreach( Ppt.Shape shape in slide.NotesPage.Shapes ) { s = GetShapeText( shape ); if( null != s ) { if( slide.SlideIndex.ToString() != s ) { notes = AppendParagraph( notes, s ); } } } // Write output for current slide. if( 0 < ( title.Length + subtitle.Length + body.Length + notes.Length ) ) { s = ( ( 0 == title.Length ) ? ( _crlf + "Slide " + slide.SlideIndex.ToString() ) : ( _crlf + ( title_prefix ? "Title: " : "" ) + title ) ) + PrependLinefeed( subtitle ) + PrependLinefeed( body ) + PrependLinefeed( notes ); sw.WriteLine( normalise_string( s.Replace( "\n", _crlf ) ) ); } } p.Close(); sw.Close(); } } return 0; } } }
I reformatted it to minimise the number of truncated overlong lines. Look at the source download below or copy to a text editor to see all the lines in full.
Ppt2txt Download
Here is ppt2txt_2.zip containing the full source code and Visual Studio solution for this utility.
I hope you find it as useful as I do.
Comments and suggestions for improvement are appreciated, as always.
Formatting in Word
One of the ppt2txt options I mentioned above was to turn off the 'Title: ' prefix.
The question is why to implement and turn it on in the first place.
Well, it prefixes each slide heading with a string saying 'Title: '.
Assuming none of my existing text already contains that exact string, I can then search and replace it globally.
In Word, I can event use search and replace to set a specific paragraph style by selecting Home > Replace > Find what: Title: > Replace with: > More>> > Format > Style... > Heading 3 > Replace All:
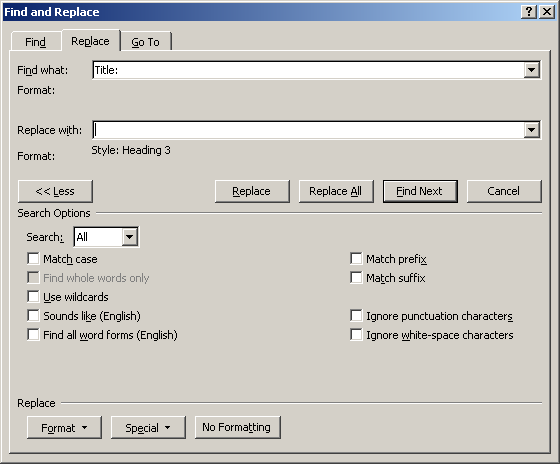
Next, I replace the same search string by an empty string with no formatting to remove all the prefixes.
I also replace duplicate paragraph end markers by single ones using the search string "^p^p" and the replacement "^p".
Sample Run
Here is the draft material that I am working on for my AU class CP4107 on the Revit 2013 UI API, including source pptx, intermediate txt, target docx and pdf renderings:
- PPTX PowerPoint slide deck.
- PDF rendering of the slide deck.
- TXT pure extracted text.
- DOCX resulting skeleton handout document.
- PDF rendering of the handout.
The handout document already contained some boilerplate text at the beginning and end before inserting the slide deck text. I replaced the 'Title: ' prefixes first by the Heading 3 paragraph style and then by empty strings to remove them. I removed all duplicate paragraph markers. That's it.
The PDF renderings of the slide deck and handout document were generated using eDocPrintPro.
My next step is obvious: add some artificial intelligence with domain knowledge, linguistic skills and good taste to create a completely finished handout fully automatically.
Enjoy, please.